原文:Medium link
中文为 AI 翻译
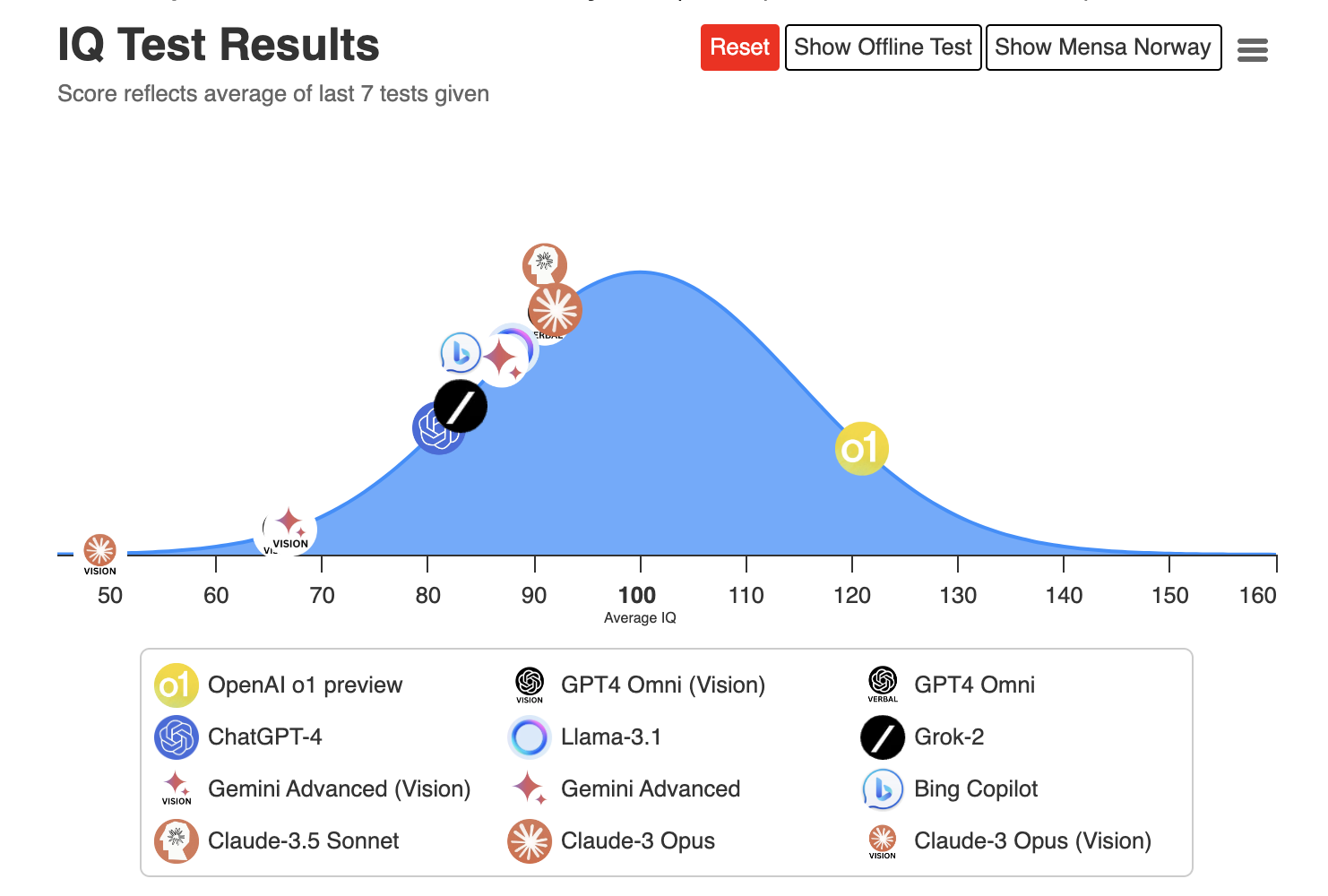
I’ve seen rankings comparing the mathematical reasoning abilities of large language models. At first, I was shocked because, in my understanding, they simply find the next word in a passage from the world’s knowledge base. LLM is based on probability calculation; their “reasoning” is to recreate or simulate how people reason, which must be recorded into text.
我看到过一些对大型语言模型数学推理能力的排名。起初,我感到震惊,因为按我的理解,它们只是从世界知识库中找出段落中的下一个词。LLM是基于概率计算的;它们的"推理"是重现或模拟人们如何推理,这必须被记录成文本。
Source: Tracking AI
LLM is trained on vast amounts of text data. If the reasoning process occurred solely in our minds, it wouldn’t be able to learn it, because it can’t read our brains like Neuralink does — a company developing a brain-machine interface to translate human thoughts. Therefore, LLM generates responses without genuine understanding or awareness of their meaning. They map statistical relationships between words instead of contemplating concepts.
LLM是在海量文本数据上训练的。如果推理过程仅发生在我们的大脑中,它就无法学习,因为它不能像Neuralink那样读取我们的大脑——这是一家开发脑机接口以翻译人类思想的公司。因此,LLM生成回应时并没有真正的理解或意识到它们的含义。它们映射的是词语之间的统计关系,而不是思考概念。
Some may argue that LLM produced creative outputs, but it’s a combination of existing data patterns. True human insight involves understanding context, emotions, and non-verbal cues, which they don’t process similarly. A Nature perspective, «Language is primarily a tool for communication rather than thought», analyzed 20 years’ research to clarify language’s role in human cognition.
有人可能会争辩说LLM产生了创造性的输出,但这只是现有数据模式的组合。真正的人类洞察力涉及理解语境、情感和非语言线索,而LLM并不以相似的方式处理这些。一篇《自然》杂志的观点文章,《语言主要是一种交流工具,而非思考工具》,分析了20年的研究,以阐明语言在人类认知中的角色。

Source: Nature
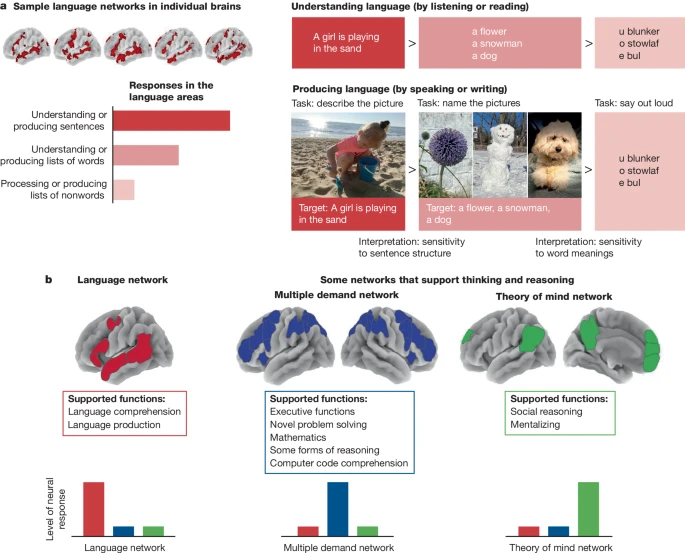
Research shows that even with impaired language ability, humans can still think differently. Neuroimages show the language network isn’t activated during non-verbal tasks, suggesting it’s separated from other cognitive functions like logical and mathematical reasoning.
研究表明,即使语言能力受损,人类仍然可以以不同方式思考。神经影像显示,在非语言任务中语言网络并未被激活,这表明语言与其他认知功能(如逻辑和数学推理)是分离的。
Source: Nature
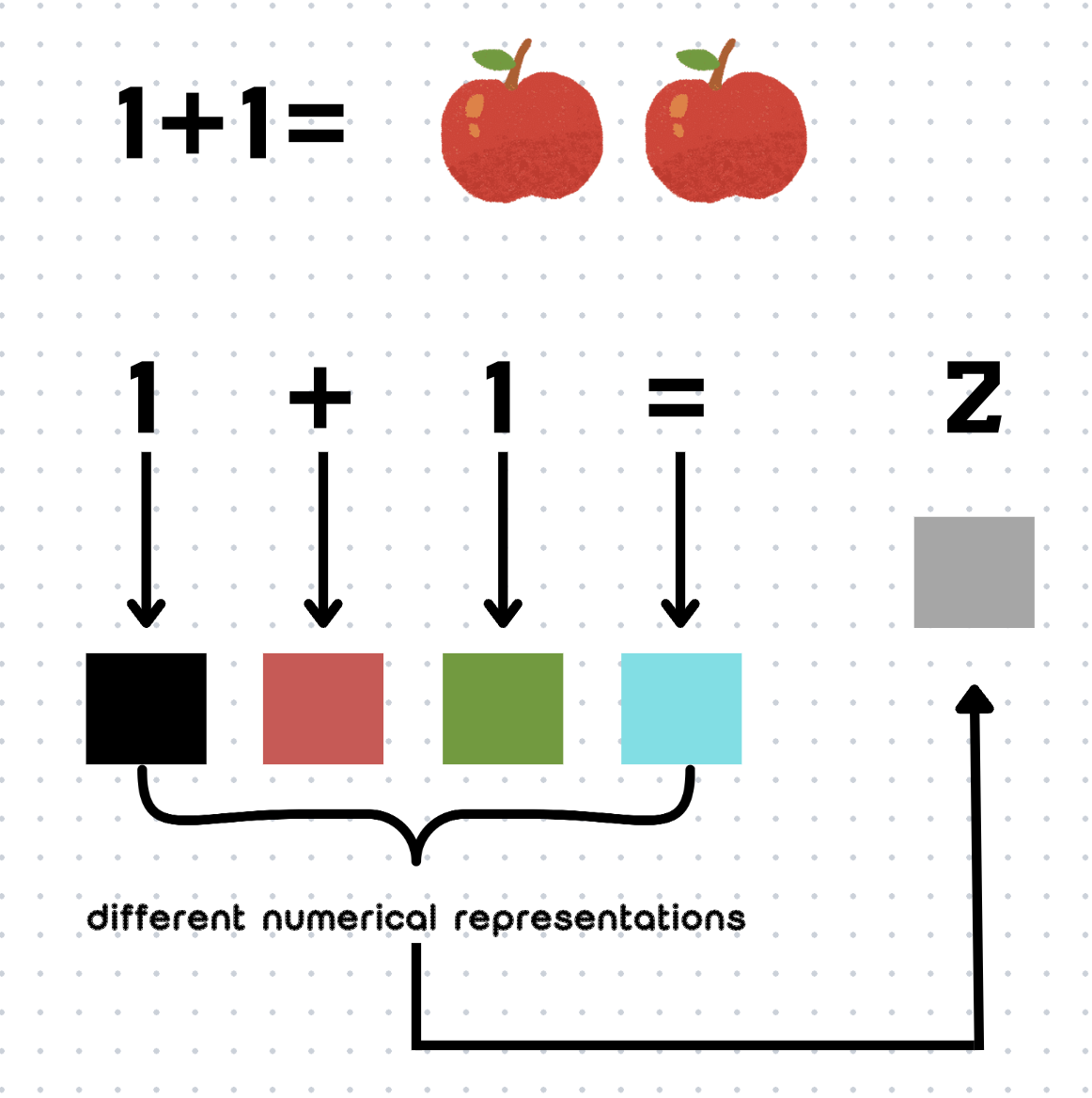
You may have insight about “language is not equal to thought” back to the title. LLM uses statistical calculation, not reasoning, to solve “1 + 1 =”. We humans know 1 plus 1; as kids, we put two apples together, then use language to express it, we say two. But LLM treats the four elements as equal, which means “token”; it finds the next element “2” with the greatest probability based on the sequential combination of these four. In a context — a dad and a mom, we may get the answer 3 or more, because they have children. LLM uses the sequential tokens to calculate the next token, so changing, adding, or deleting will change the answer.
你可能会将"语言不等同于思维"这一见解联系到标题。LLM使用统计计算而非推理来解决"1 + 1 ="。我们人类知道1加1;小时候,我们把两个苹果放在一起,然后用语言表达它,我们说两个。但LLM将这四个元素视为平等的,称之为"token";它基于这四个元素的顺序组合,找出概率最大的下一个元素"2"。在一个语境中——一个爸爸和一个妈妈,我们可能得到3或更多的答案,因为他们有孩子。LLM使用连续的token来计算下一个token,所以改变、添加或删除都会改变答案。
Chain of thought (CoT) is advocated for LLMs, based on Daniel Kahneman’s System 1 (fast, intuitive) and System 2 (slow, deliberate) thinking in “Thinking, Fast and Slow.” Many think current AI mainly uses System1, while CoT prompts can instruct it to use System 2 mindset with words like “let’s think step by step.” In a paper, researchers found that “let’s think step by step” led to 11% more accuracy than “let’s solve the problem“ in domains from mathematical to logical reasoning tasks.
思维链(CoT)被倡导用于大型语言模型,这基于丹尼尔·卡尼曼在《思考,快与慢》中提出的系统1(快速、直觉的)和系统2(缓慢、深思熟虑的)思考方式。许多人认为当前的人工智能主要使用系统1,而CoT提示可以指导它使用系统2的思维方式,比如使用"让我们一步一步地思考"这样的词语。在一篇论文中,研究人员发现,在从数学到逻辑推理任务的领域中,"让我们一步一步地思考"比"让我们解决问题"的准确率高出11%。
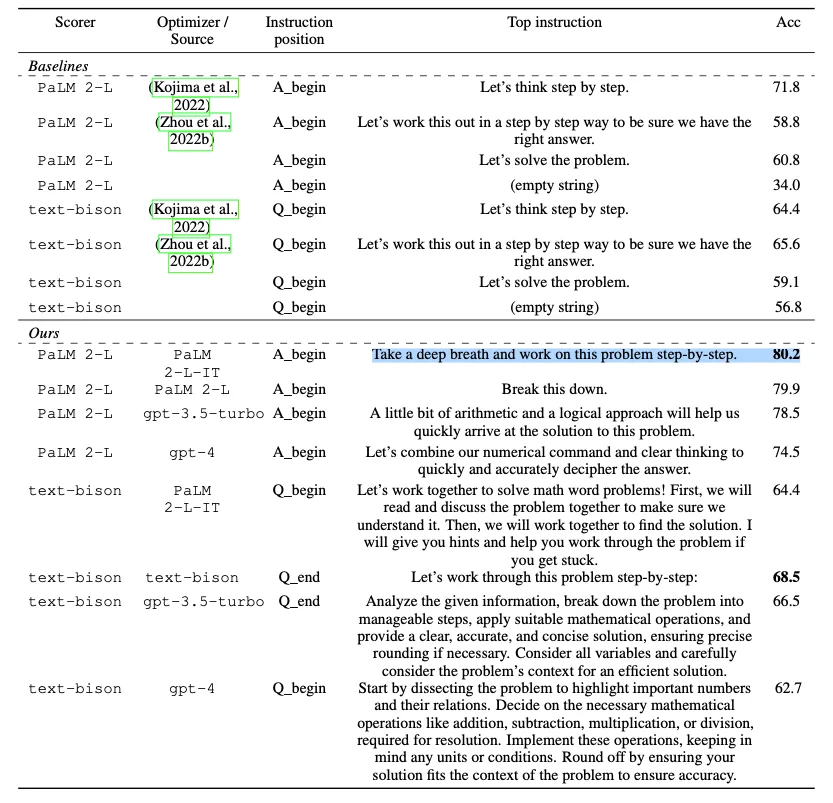
Source:Arxiv
Adding such prompts changes the answer. In the picture below, the CoT-prompted chatbot can provide a detailed process and give a correct answer most of the time. The research demonstrated that on the GSM8K benchmark of 8,500 grade school math problems, accuracy was four times higher using CoT reasoning compared to standard prompting. It emerges in larger language models.
添加这样的提示会改变答案。在下图中,使用CoT提示的聊天机器人能够提供详细的过程,并在大多数情况下给出正确答案。研究表明,在GSM8K基准测试的8,500道小学数学问题中,使用CoT推理的准确率比标准提示高出四倍。这种现象在更大的语言模型中尤为明显。
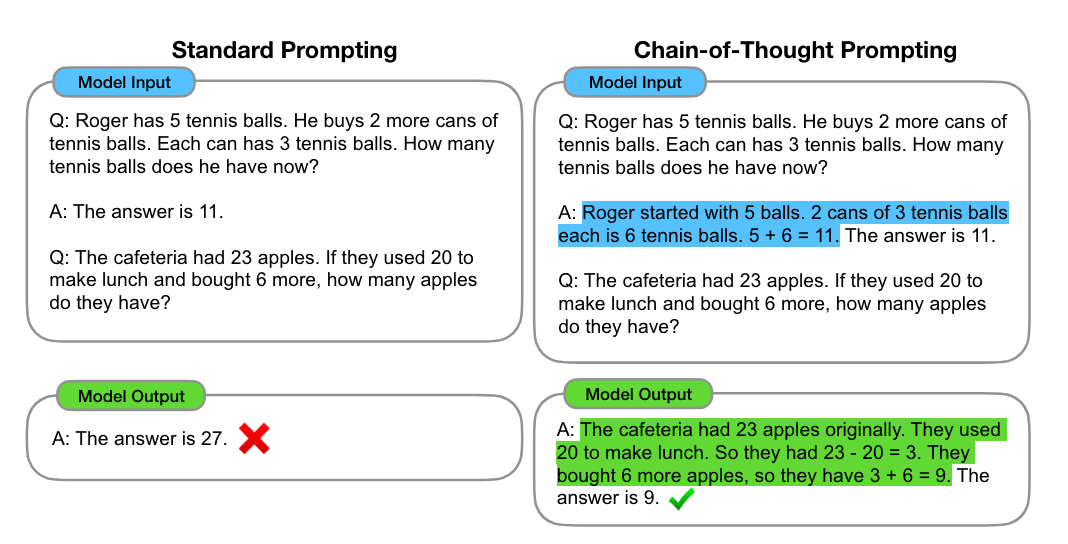
Source:Arxiv
I said LLMs can’t think, but why chain of thought works. Based on my knowledge, there’s an imprecise conjecture in my brain — step-wise probability reinforcement, cool name lol. A CoT prompt causes the model to generate the first tokens, the ones for the first step, then the second, and so on until the final result.
我说过LLM无法思考,但为什么思维链有效呢?根据我的理解,我脑中有一个不太精确的猜想——逐步概率强化,这名字很酷吧,哈哈。CoT提示使模型生成第一步的token,然后是第二步,以此类推直到最终结果。

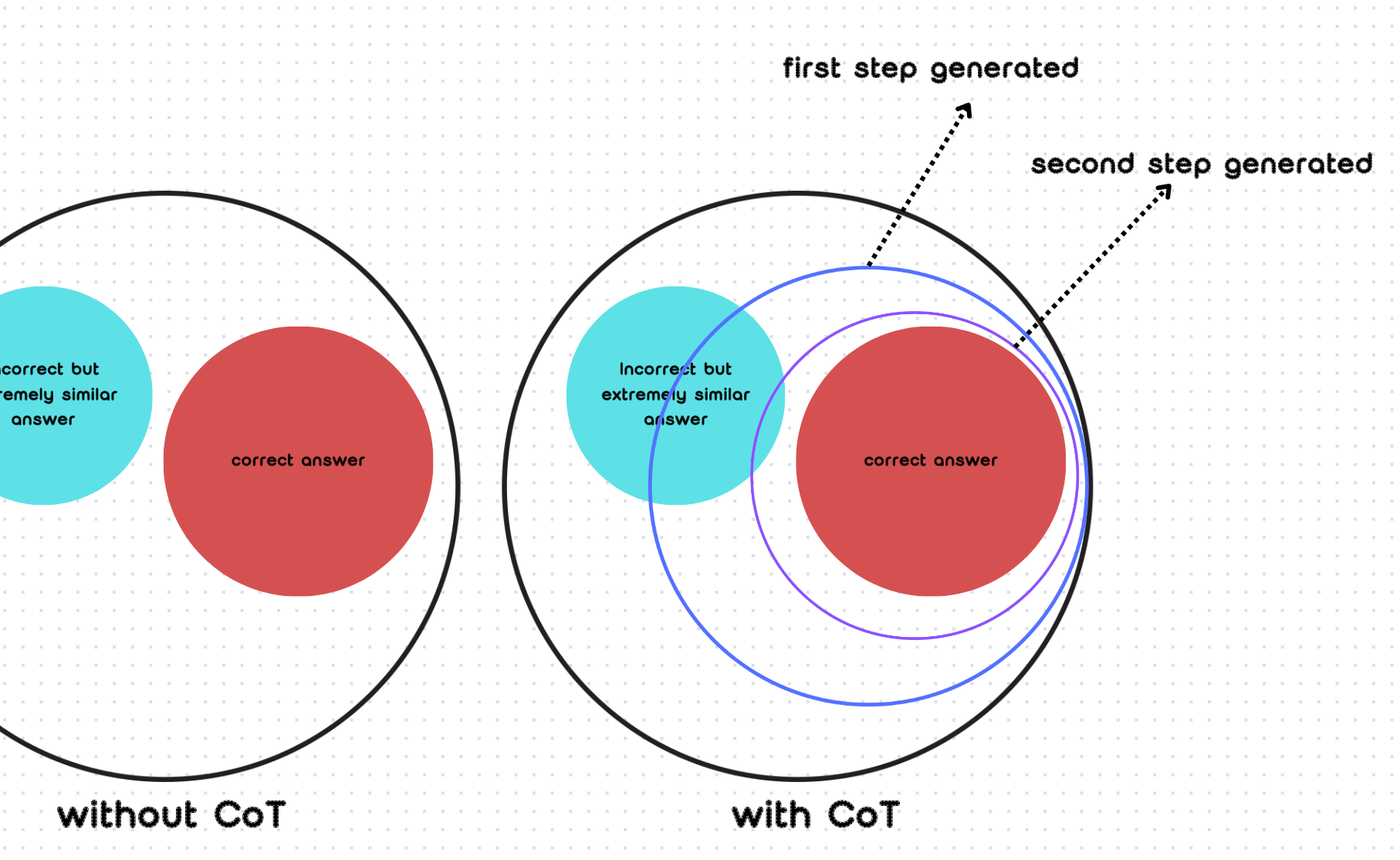
Using the CoT prompt reinforces the first step’s word probability to be the first generated tokens. Then, the generated words and CoT prompt reinforce the second step’s words. It narrows down the correct answer range step by step. As shown in the image below, in general situations without using CoT, when calculating possibilities, multiple results with two or more levels of possibility may appear. In this case, it’s easy to choose an answer that is extremely similar but incorrect. While we use CoT, when generating the first result, it reinforces its probability, so it will narrow down the range more. Then, when generating the second choice circle, it will narrow down even further, gradually approaching the true result step by step. We can see that there's still a certain probability of selecting an incorrect answer in the end, but this probability is very small.
使用CoT提示会强化第一步词语的概率,使其成为首先生成的token。然后,生成的词语和CoT提示会强化第二步的词语。它逐步缩小正确答案的范围。如下图所示,在不使用CoT的一般情况下,在计算可能性时,可能会出现具有两个或更多可能性级别的多个结果。在这种情况下,很容易选择一个极其相似但不正确的答案。而当我们使用CoT时,在生成第一个结果时,它会强化其概率,因此会更多地缩小范围。然后,在生成第二个选择圈时,它会进一步缩小范围,逐步接近真实结果。我们可以看到,最终选择错误答案的概率仍然存在,但这个概率非常小。
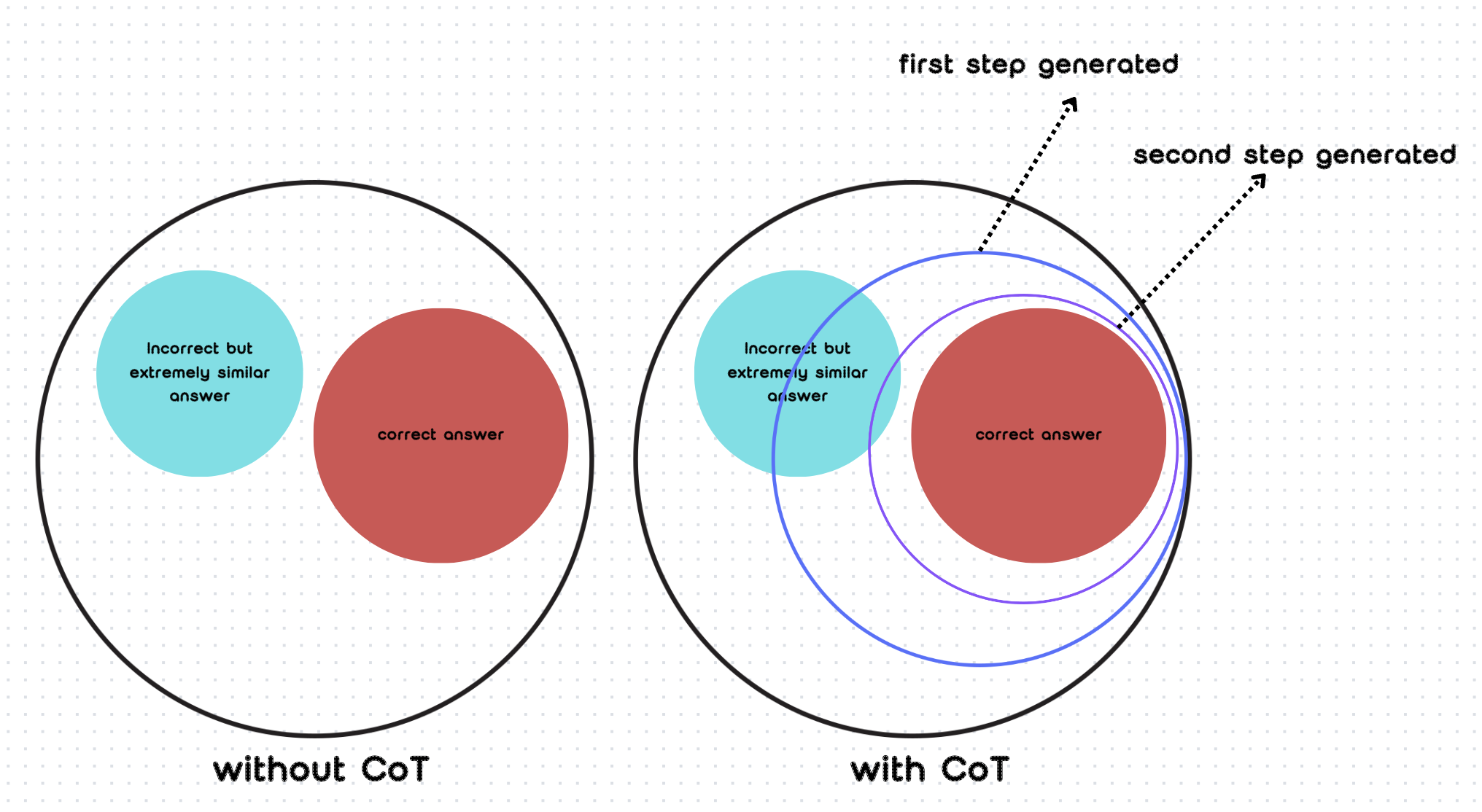
Thus, I think using CoT does not really let LLMs think step by step. Instead, it just changes the calculation of the probability of the tokens to be generated.
因此,我认为使用CoT并不是真正让LLM逐步思考。相反,它只是改变了将要生成的token的概率计算。
I’d like to clarify that the above is merely my speculation, not an attempt to explore the LLMs’ complex and not fully understood mechanism (black box). The professional mechanisms are not being investigated; this is my personal viewpoint, so welcome discussion or challenges.
我想澄清的是,以上仅仅是我的推测,并非试图探索LLM复杂且尚未完全理解的机制(黑盒)。这里没有对专业机制进行调查;这只是我个人的观点,所以欢迎讨论或质疑。
citation:
Fedorenko, E., Piantadosi, S.T. & Gibson, E.A.F. Language is primarily a tool for communication rather than thought. Nature 630, 575–586 (2024). https://doi.org/10.1038/s41586-024-07522-w
Yang, C., Wang, X., Lu, Y., Liu, H., Le, Q. V., Zhou, D., & Chen, X. (2023, September 7). Large Language Models as Optimizers. arXiv. https://arxiv.org/abs/2309.03409
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv. https://arxiv.org/abs/2201.11903