
This week we’re bringing you some of our best writing on how to use AI by Michael Taylor, whose new column, *Also True for Humans, examines how we work with and manage AI tools like we would human coworkers. (He’s also the co-author of a new book,* Prompt Engineering for Generative AI.) Up today is this exploration of how AI is helping us know when to follow the herd and when to chart a new path.—Kate Lee
本周我们为您带来一些关于如何使用人工智能的精选文章,作者是Michael Taylor。他的新专栏《对人类也适用》探讨了我们如何像管理人类同事一样使用和管理人工智能工具。(他也是新书《生成式人工智能提示工程》的合著者。)今天为您带来的是这篇探索,讲述人工智能如何帮助我们知道何时跟随大众,何时开辟新路。——Kate Lee
Walking into a coffee shop in Brooklyn or Bangkok, Des Moines or Dublin, you might notice some commonalities. You wouldn’t be surprised to see reclaimed wood furniture, hanging Edison bulbs, and minimalistic design choices. There might be elaborately tattooed baristas and indie folk music playing in the background.
无论是在布鲁克林还是曼谷,得梅因还是都柏林,走进一家咖啡店,你可能会注意到一些共同点。看到回收木材制成的家具、悬挂的爱迪生灯泡和极简主义的设计风格,你不会感到惊讶。可能还会有纹身复杂的咖啡师,背景音乐播放着独立民谣。
This isn’t a mistake. Sameness is a powerful thing. Customers learn to look out for visual cues, which signal whether they’re in the right place or not.
这并非巧合。相似性是一种强大的力量。顾客学会寻找视觉线索,这些线索能够表明他们是否来到了合适的地方。
There isn’t a global conspiracy to make all coffee shops look alike. It’s just that the internet has connected our world in a way that social media algorithms propel winning combinations to the whole world, flattening our culture, as Kyle Chayka writes in his book Filterworld. Ignore convention at your peril.
并不存在一个让所有咖啡店看起来相似的全球阴谋。只是互联网以这样一种方式连接了我们的世界,社交媒体算法将成功的组合推广到全世界,正如Kyle Chayka在他的著作《过滤世界》中所写的那样,这使我们的文化变得扁平化。忽视惯例会让你处于危险之中。
Tapping into design cues, if implemented correctly, can remove some of the risk and uncertainty that comes with starting a new business. The key is to know when to be similar and when to be different.
如果能正确运用设计线索,可以消除开设新业务时带来的一些风险和不确定性。关键在于知道何时保持相似,何时要有所不同。
That matters because, according to the U.S. Bureau of Labor Statistics, 90 percent of startups fail, a data point that has remained consistent since the 1990s. But entrepreneurs who have started a successful business in the past are three times more likely to succeed the second time around. Experiencing success seems to lead to more success. As we established in part one of this series, artificial intelligence can help entrepreneurs compensate for a lack of experience by helping summarize and analyze the lessons from others’ success. It can find the sameness so you can exploit it.
这一点很重要,因为根据美国劳工统计局的数据,90%的创业公司都会失败,这个数据自20世纪90年代以来一直保持不变。但是,曾经成功创业的企业家在第二次创业时成功的可能性要高出三倍。经历成功似乎会带来更多的成功。正如我们在本系列的第一部分中所确立的那样,人工智能可以帮助企业家弥补经验不足的缺陷,通过帮助总结和分析他人的成功经验。它可以找出相似之处,让你能够加以利用。
If you’re opening that coffee shop—in any city—you need to make strategic decisions about how similar or different it should be from consumer expectations. Finding the right balance could mean the difference between starting a beloved café and investing in a money pit.
如果你正在任何城市开设咖啡店,你需要做出战略性决策,确定它应该与消费者期望有多相似或不同。找到正确的平衡可能意味着成功创办一家备受喜爱的咖啡馆和投资一个亏损项目之间的区别。

Source: Alex Murrell.
Memetic analysis with GPT-4V
用GPT-4V进行模因分析
This flattening of culture doesn’t just apply to coffee shops. In his essay, “The Age of Average,” Alex Murrell found the same effect in everything from the design of cars to architecture to Airbnbs: If you deviate too far from what customers expect, you might become one of the 90 percent of new businesses that fails. You don’t have to adopt every fad or stereotype, but you need to know what risks you’re taking when you decide to differentiate. From a practical perspective, you’d want to look at lots of examples of other coffee shops until you notice patterns in their similarities and differences—aka memetic analysis.
这种文化的趋同现象不仅仅适用于咖啡店。在他的文章《平均化时代》中,Alex Murrell发现从汽车设计到建筑再到Airbnb房源,都存在同样的效应:如果你偏离客户期望太远,你可能会成为那90%失败的新企业之一。你不必跟随每一种时尚或刻板印象,但当你决定要有所不同时,你需要知道你正在承担什么风险。从实际角度来看,你需要观察大量其他咖啡店的例子,直到你注意到它们在相似性和差异性上的模式——这就是所谓的模因分析。
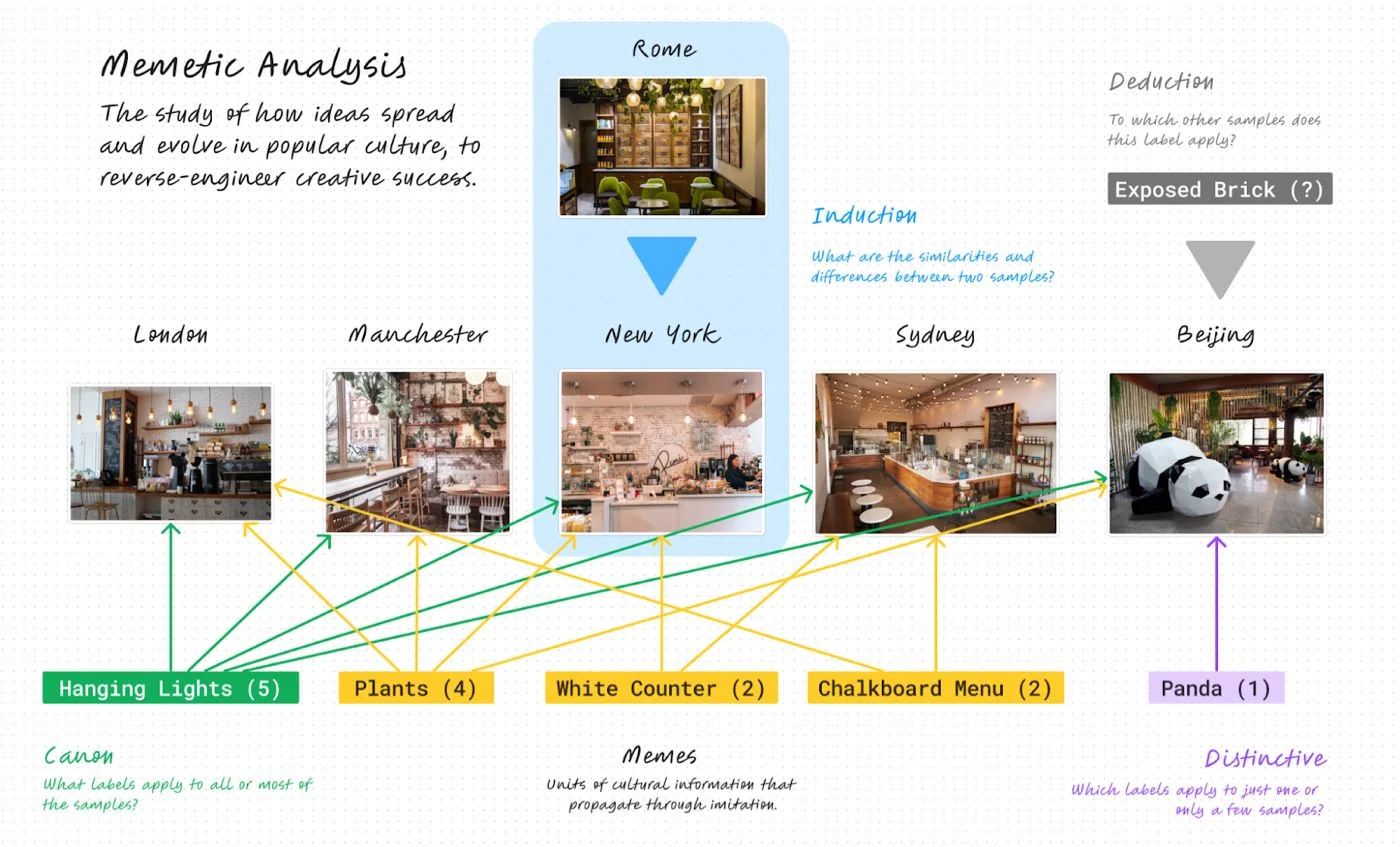
Source: The author.
Memetic analysis is rooted in grounded theory, which is a method for deriving insights from the data you have collected. It’s an iterative process starting with inductive coding, in which you identify similarities and differences between different samples. If we compare a coffee shop in Rome to one in New York, we might find the one in Rome features green upholstered seats, leather-bound books, and rich mahogany furniture, while the one in New York has white plastic chairs, exposed brick walls, and marble countertops. They may both have green plants, dangling pendant lights, and an iPad attached to its cash register.
模因分析源于扎根理论,这是一种从收集的数据中获取洞察的方法。它是一个迭代过程,始于归纳编码,在这个过程中,你识别不同样本之间的相似性和差异性。如果我们比较罗马的一家咖啡店和纽约的一家,我们可能会发现罗马的那家特色是绿色软垫座椅、皮面装订的书籍和豪华的红木家具,而纽约的那家则有白色塑料椅子、裸露的砖墙和大理石台面。它们可能都有绿色植物、悬挂的吊灯,以及连接到收银机的iPad。
Do this enough times for different pairings, and you’ll get a database of labels—also called codes or memes—that you can use for deductive coding, or finding what other samples from your database share these attributes (i.e., how many coffee shops have exposed brick?). This is boring, manual work, especially when you have hundreds or thousands of samples to sift through. Thankfully, since ChatGPT was upgraded to “see” images—called GPT-4V for developers, and the “v” is for vision—)—AI can help automate this process:
如果对不同的配对重复这个过程足够多次,你就会得到一个标签数据库——也称为代码或模因——你可以用它来进行演绎编码,即找出你数据库中的其他样本共享哪些属性(例如,有多少咖啡店有裸露的砖墙?)。这是一项枯燥的手工工作,尤其是当你需要筛选数百或数千个样本时。幸运的是,自从ChatGPT升级为能够"看到"图像——开发者称之为GPT-4V,"v"代表视觉——人工智能可以帮助自动化这个过程:

Source: Screenshots courtesy of the author.
Here’s the prompt I used:
Compare these two coffee shops using inductive coding. What features, attributes, or elements of the design are similar or different? Give a markdown table with a descriptive label name, coffee shop A and coffee shop B as columns, and one row per label. The value of the column for each coffee shop should be 1 if the label applies to this coffee shop, or zero if it doesn't. If the label applies to both coffee shops, it should be 1 in both columns. Only output the markdown table.
以下是我使用的提示:
使用归纳编码比较这两家咖啡店。设计的特征、属性或元素有哪些相似或不同之处?给出一个markdown表格,包含描述性的标签名称,咖啡店A和咖啡店B作为列,每个标签占一行。如果该标签适用于这家咖啡店,则该列的值为1,否则为零。如果该标签适用于两家咖啡店,则两列都应为1。只输出markdown表格。
ChatGPT can save us a lot of time, and might potentially be more consistent and less biased than a human rater. However, even though ChatGPT saves us time where we might otherwise rely on manual review, it’s still tedious for a human to need to upload two images at a time, copy and paste all the labels into a spreadsheet, and repeat the process a few hundred times. Thus, knowing how to code (or working with someone who does) can come in handy, because you can access GPT-4V (the developer version of ChatGPT) to process thousands of these requests in minutes, rather than doing everything yourself.
ChatGPT可以为我们节省大量时间,而且可能比人工评估更加一致和客观。然而,尽管ChatGPT在我们可能需要依赖手动审查的地方为我们节省了时间,但对于人类来说,每次上传两张图片、将所有标签复制粘贴到电子表格中,然后重复这个过程几百次仍然是一项繁琐的工作。因此,懂得编程(或与懂编程的人合作)会很有帮助,因为你可以访问GPT-4V(ChatGPT的开发者版本)来在几分钟内处理成千上万的这类请求,而不是自己做所有的事情。
I won’t bore you with the code, but at a high level, here are the steps:
我不会用代码来烦你,但从宏观层面来说,以下是步骤:
1. Scrape images from the web
从网上抓取图片
To get the images for the analysis, I used a free Google Images scraping script, added my list of keywords to the main.py file, and downloaded the Chrome Web Driver to the folder, before running the script. I only ran it for 15 minutes, but I could have left it on overnight to catalog many more images.
为了获取分析所需的图片,我使用了一个免费的Google图片抓取脚本,将我的关键词列表添加到main.py文件中,并在运行脚本之前将Chrome Web Driver下载到文件夹中。我只运行了15分钟,但如果让它运行整晚,可以编目更多的图片。
2. Change the output format to JSON
将输出格式更改为JSON
I changed the prompt to output JSON (a data format) instead of a markdown table, and wrote a simple Python script I can run on any two coffee shops to get structured data back with their labels. Most developers do prompting this way, because it’s easier to make use of the results when they’re in a consistent data format. From JSON, you can easily use the data as input for another script, display it on a web page, or export it into a CSV file.
我将提示更改为输出JSON(一种数据格式)而不是markdown表格,并编写了一个简单的Python脚本,可以在任何两家咖啡店上运行以获取带有标签的结构化数据。大多数开发人员都以这种方式进行提示,因为当结果采用一致的数据格式时,更容易使用。从JSON中,你可以轻松地将数据用作另一个脚本的输入、在网页上显示,或导出为CSV文件。
3. Run deductive coding on the labels
对标签进行演绎编码
With the list of labels I got back, I then ran the deductive coding step to check every label against every coffee shop, and see what percentage they applied to. This step took the most time because I had to check every label against every image, and all of those calls to OpenAI add up. You can speed this part up by making the code asynchronous, which just means sending more than one request to OpenAI at a time, which are processed simultaneously (like a supermarket opening more checkout lanes to decrease the time spent waiting in line).
获得标签列表后,我接着进行了演绎编码步骤,检查每个标签是否适用于每家咖啡店,并查看它们的适用百分比。这一步骤耗时最长,因为我必须对照每张图片检查每个标签,而所有这些对OpenAI的调用都会累积起来。你可以通过使代码异步来加快这部分的速度,这意味着同时向OpenAI发送多个请求,这些请求会被同时处理(就像超市开设更多收银通道以减少排队等待时间一样)。
4. Interpret the analysis and take action
解读分析并采取行动
Summing up the number of times each label appeared across our list of coffee shop images gives us some indication of what was popular and what wasn’t. Labels that appear in every coffee shop may be important to copy, and labels that appear infrequently might give us inspiration for where to differentiate.
总结我们咖啡店图片列表中每个标签出现的次数,可以给我们一些关于什么是流行的和不流行的指示。在每家咖啡店都出现的标签可能是重要的需要模仿的元素,而很少出现的标签可能给我们提供了差异化的灵感。
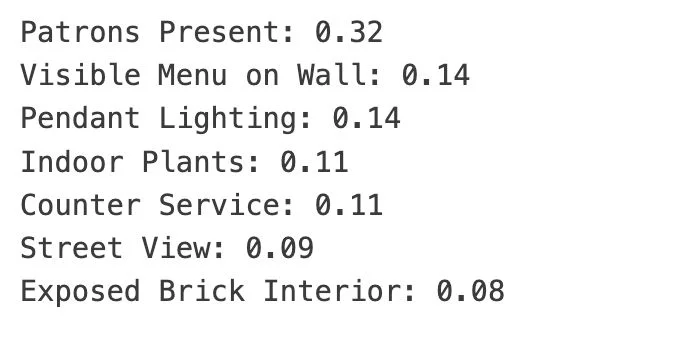
Since 32 percent of coffee shop photos show patrons, I can keep that in mind while taking photos of my own coffee shop for its website. I also see that only around 8 percent of coffee shop images have an exposed brick interior, but 14 percent show pendant lighting. That’s surprising—I would have thought each was more popular. Take notes when you’re surprised, because it’s a sign the assumptions are wrong or need updating.
由于32%的咖啡店照片展示了顾客,我在为自己的咖啡店网站拍摄照片时可以将这一点牢记在心。我还注意到,只有约8%的咖啡店图片有裸露的砖墙内饰,但14%展示了吊灯。这很令人惊讶——我原本以为这两者都会更受欢迎。当你感到惊讶时,要记下来,因为这表明你的假设可能是错误的或需要更新
It took me about 100 lines of code, using OpenAI’s documentation, to generate a qualitative analysis of 564 images of coffee shops from around the world. It likely saved me a week’s worth of time—minus 30 minutes to write and run the code—assuming I would even have the stamina to meticulously catalog comparisons between hundreds of coffee shops. Plus, I’ve now seen hundreds more coffee shop designs in far more detail than any of my competitors, giving me an advantage in designing a coffee shop that resonates with customers.
我用了大约100行代码,使用OpenAI的文档,对来自世界各地的564张咖啡店图片进行了定性分析。这可能为我节省了一周的时间——减去写代码和运行代码的30分钟——假设我甚至有耐心去精心编目数百家咖啡店之间的比较。此外,我现在比任何竞争对手都更详细地看到了数百种咖啡店设计,这让我在设计一家能引起顾客共鸣的咖啡店时具有优势。
I recently used this method while building an Udemy course, which is now the top prompt engineering course on the platform. I identified what sorts of titles, descriptions, and course structures were correlated with more reviews (a proxy for sales), and designed the entire course based on what works best on the platform. I can’t know how I would have done without memetic analysis, but it was half a day’s extra work for a project that ended up paying my mortgage. You can hope to get lucky, or you can use memetic analysis to rig the game in your favor.
我最近在制作一个Udemy课程时使用了这种方法,该课程现在是平台上排名第一的提示工程课程。我识别了哪些类型的标题、描述和课程结构与更多评论(作为销售的代理指标)相关,并基于平台上最有效的方式设计了整个课程。我无法确知如果没有模因分析我会做得如何,但这项额外半天的工作最终为一个能够支付我房贷的项目做出了贡献。你可以寄希望于运气,也可以利用模因分析来让局势对你更加有利。
What to copy and where to differentiate
该复制什么,在哪里进行差异化
No matter what industry in which you’re operating, you need to make informed, strategic decisions about what conventions you’ll adopt and where you want to innovate, where you’ll zig and where you’ll zag.
无论你在哪个行业运营,你都需要做出明智的战略决策,确定要采用哪些惯例,以及在哪些方面进行创新,在哪里顺势而为,在哪里逆势而行。
The case for copying
复制的理由
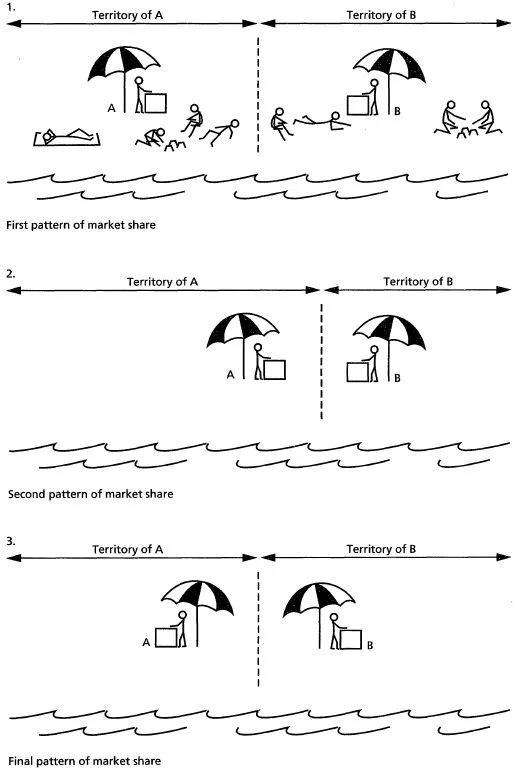
You should default to covering the majority of the common attributes your analysis found, because it almost always makes sense to copy your competitors closely. Hotelling’s law uses game theory to explain why most competitors physically move closer together over time, using an example of ice cream vendors on a beach. If seller A starts at one end of the beach and seller B is at the other end, seller A can claim more sales by moving closer to the middle, because they will be the nearest vendor to a larger share of the beach. At equilibrium, both sellers end up in the middle, right next to each other, which is why you so often see Burger King and Wendy’s crop up next to McDonald’s on the same street. This law doesn’t just apply to location, but also to branding, features, and anything else that affects a consumer’s likelihood of buying a product.
你应该默认涵盖分析中发现的大多数常见属性,因为紧密模仿你的竞争对手几乎总是有意义的。霍特林法则使用博弈论来解释为什么大多数竞争对手随着时间的推移会在物理位置上越来越接近,以沙滩上的冰淇淋销售商为例说明这一点。如果销售商A从沙滩的一端开始,销售商B在另一端,销售商A可以通过向中间移动来争取更多销售,因为他们将成为更大份额沙滩区域最近的供应商。在平衡状态下,两个销售商最终都会在中间,紧挨着对方,这就是为什么你经常看到汉堡王和温迪快餐店在同一条街上紧挨着麦当劳开业的原因。这个法则不仅适用于位置,还适用于品牌、功能以及任何影响消费者购买产品可能性的因素。
Source: *Vivify.*
Where do you differentiate?
在哪里进行差异化?
It’s easy to recall examples where competitors in an industry have become commoditized and more or less the same, but if it’s always rational to converge on the middle of the market to gain the most market share, why is product differentiation such a powerful strategy?
很容易回想起一个行业中竞争对手变得商品化并且几乎相同的例子,但如果总是理性地趋向于市场中间以获得最大的市场份额,为什么产品差异化会是如此强大的策略?
In the beach example, both vendors sold ice cream, and the customers didn’t care who they bought it from. In reality, there’s not just one undifferentiated mass of consumers: they are made up of different segments with unique preferences. Most like vanilla, chocolate, or strawberry, but enough people like birthday cake flavored ice cream that a seller can win more customers by being the only one to offer it. Wherever there is a real difference between what one segment prefers and what the mainstream consumer wants on average, there’s an opportunity for differentiation. Differentiation comes with danger: offering birthday cake ice cream means not offering a more popular flavor, and may even put some customers off. Every decision to cater to a specific niche risks decreasing the size of your target market, so it’s only a viable strategy for the smaller players that would otherwise be crushed by the scale advantages of larger players.
在沙滩的例子中,两个供应商都卖冰淇淋,顾客并不在意从谁那里购买。实际上,消费者并不是一个毫无差别的整体:他们由具有独特偏好的不同群体组成。大多数人喜欢香草、巧克力或草莓口味,但也有足够多的人喜欢生日蛋糕口味的冰淇淋,以至于一个销售商可以通过成为唯一提供这种口味的人来赢得更多顾客。只要某个群体的偏好与主流消费者的平均需求之间存在真正的差异,就有差异化的机会。差异化伴随着风险:提供生日蛋糕口味的冰淇淋意味着不提供更受欢迎的口味,甚至可能会让一些顾客望而却步。每一个迎合特定利基市场的决定都有可能减少你的目标市场规模,所以这只是对那些否则会被大型企业的规模优势碾压的小型企业来说才是可行的策略。
In the craft beer industry, smaller U.S. breweries were driven to near-extinction by beer behemoths. Mass production made beer cheap to produce and left room for huge national advertising budgets, which, in turn, increased the scale of production, leading to further cost and distribution savings, until the large breweries had what seemed like an insurmountable advantage.
在精酿啤酒行业,美国的小型啤酒厂曾几乎被啤酒巨头驱逐至灭绝。大规模生产使啤酒生产成本降低,并为巨额全国广告预算留出了空间,这反过来又增加了生产规模,导致进一步的成本和分销节省,直到大型啤酒厂似乎拥有了不可逾越的优势。
Craft breweries survived by occupying an ecological niche—differentiating in flavor, such as adding more hops, or brewing with fruits and spices—which the big breweries were unwilling to do. In order to cater to different flavor profiles, they brewed in smaller batches, eliminating their cost advantage. Dedicated craft beer drinkers were less price-sensitive, willing to pay a premium for more flavorful beer, even making the purchase part of their identity. The key is that it has to be a real differentiator, not just slapping a different label on the bottle; otherwise it wouldn’t have been prohibitively costly for the big breweries to counter.
精酿啤酒厂通过占据生态位而存活下来——在口味上进行差异化,比如添加更多啤酒花,或者用水果和香料酿造——这是大型啤酒厂不愿意做的。为了迎合不同的口味偏好,他们以小批量酿造,放弃了成本优势。忠实的精酿啤酒饮用者对价格不太敏感,愿意为更有风味的啤酒支付溢价,甚至将购买行为作为他们身份的一部分。关键是这必须是真正的差异化,而不仅仅是在瓶子上贴上不同的标签;否则,大型啤酒厂就不会因为成本过高而无法应对。
Getting the timing right
把握时机
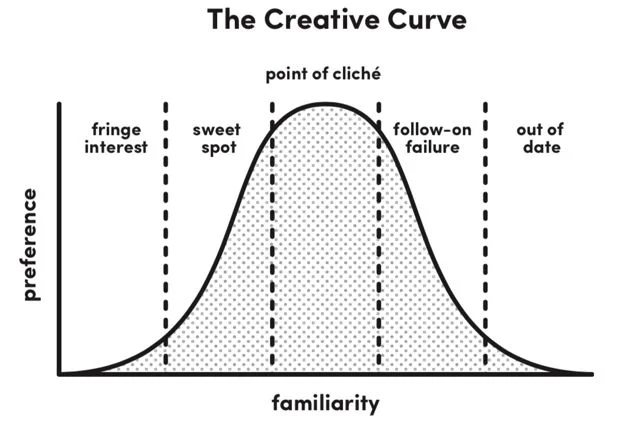
Nobody can predict when an evolutionary leap will occur in an industry, but if you dig deep into fringe communities you can figure out when to react, as marketing executive Allen Gannett demonstrated in his book, The Creative Curve.
没人能预测一个行业何时会发生进化性的飞跃,但如果你深入研究边缘社群,你就能弄清楚何时该做出反应,正如营销主管艾伦·甘尼特在他的著作《创意曲线》中所展示的那样。
Source: The Creative Curve.
Gannett’s curve starts within fringe communities, where some small market segment starts to care about a specific feature or basket of attributes enough to pay a premium. In your analysis, you can find this by paying attention to labels that appear only a small handful of times. Adopting one of these differentiators is the riskiest proposition, because most fringe interests stay fringe. However, if you spot a number of coffee shops adopting something that wasn’t that popular a year ago, you might have found something in the sweet spot between preference and familiarity: just familiar enough to go mainstream, but differentiated enough to help you stand out in a particular segment of the market. These so-called vibe shifts occur through a form of cultural natural selection in the evolution of ideas, as the old way of doing things becomes saturated, causing influential players in the space to find something new.
甘尼特的曲线始于边缘社群,在这里,一些小型市场细分开始关注某个特定特征或一系列属性,甚至愿意为此支付溢价。在你的分析中,你可以通过关注那些仅出现少数几次的标签来发现这一点。采用这些差异化因素之一是最冒险的做法,因为大多数边缘兴趣仍然停留在边缘。然而,如果你发现一些咖啡店开始采用一年前并不流行的东西,你可能已经发现了介于偏好和熟悉度之间的最佳点:刚好足够熟悉以进入主流,但又足够与众不同,能帮助你在特定市场细分中脱颖而出。这种所谓的氛围转变是通过一种文化自然选择在思想演变中发生的,当旧有的做事方式变得饱和时,就会促使该领域有影响力的参与者寻找新的东西。
Remixing ideas to make something new
混合创意打造新事物
Say you notice that more and more fitness enthusiasts are grabbing protein shakes with coffee in them for a post-workout boost. You might seize the opportunity to be the only non-hipster coffee shop, capitalizing on this trend by decorating your coffee shop like a CrossFit gym or SoulCycle studio.
假设你注意到越来越多的健身爱好者在锻炼后喝含咖啡因的蛋白奶昔来提神。你可能会抓住这个机会,成为唯一一家非文青咖啡店,利用这一趋势将你的咖啡店装饰成CrossFit健身房或SoulCycle单车教室的风格。
But even when differentiating yourself from the rest of your category, be careful to copy the right design elements that will resonate with your target customers. For example, Hotel Chocolat creative director Fredrik Ahlin chose not to compete with fellow chocolatiers, and instead decorated its stores like a high-end makeup store, advertising in Vogue to signal to its intended clientele that this was a place they belonged. Much of what we call innovation is just combining ideas from multiple sources.
但即使在与同类区分开来时,也要注意复制那些能引起目标客户共鸣的正确设计元素。例如,Hotel Chocolat的创意总监Fredrik Ahlin选择不与其他巧克力制造商竞争,而是将其商店装饰成高端化妆品店的样子,并在Vogue杂志上做广告,向目标客户群传达这是他们归属之地的信息。我们所称的创新,很多时候只是将来自多个源头的想法结合在一起。

Source: *In the Zeitgeist/Fredrik Ahlin.*
While following the crowd and adopting industry norms is a safe strategy, true innovation often requires going against the grain. Successful differentiation involves identifying and catering to the unique preferences of a specific market segment, and taking the risk of deviating from the mainstream. No analysis can tell you what to do—you still have to decide for yourself. However, by conducting memetic analysis and staying attuned to emerging trends and fringe interests, you can spot opportunities that others missed and make more informed creative decisions. Nothing can guarantee creative success, but memetic analysis can increase your odds.
虽然跟随大众和采用行业规范是一种安全的策略,但真正的创新往往需要逆流而上。成功的差异化包括识别并迎合特定市场细分的独特偏好,并冒险偏离主流。没有任何分析能告诉你该怎么做——你仍然需要自己做决定。然而,通过进行模因分析并密切关注新兴趋势和边缘兴趣,你可以发现他人错过的机会,并做出更明智的创意决策。虽然没有什么能保证创意成功,但模因分析可以提高你的成功几率。
After all, you have to know the rules in order to break them.
毕竟,你必须先了解规则,才能打破它们。